:Let us consider a shallower architecture and its deeper counterpart that adds more layers onto it. There exists a solution by construction to the deeper model: the added layers are identity mapping, and the other layers are copied from the learned shallower model.
As this is an academic paper this process is described in a rather inaccessible way, but the concept is actually very simple: start with a 20-layer neural network that is trained well, and add another 36 layers that do nothing at all (for instance, they could be linear layers with a single weight equal to 1, and bias equal to 0). The result will be a 56-layer network that does exactly the same thing as the 20-layer network, proving that there are always deep networks that should be at least as good as any shallow network. But for some reason, SGD does not seem able to find them.
jargon:Identity mapping: Returning the input without changing it at all. This process is performed by an identity function.
Actually, there is another way to create those extra 36 layers, which is much more interesting. What if we replaced every occurrence of conv(x) with x + conv(x), where conv is the function from the previous chapter that adds a second convolution, then a batchnorm layer, then a ReLU. Furthermore, recall that batchnorm does gamma*y + beta. What if we initialized gamma to zero for every one of those final batchnorm layers? Then our conv(x) for those extra 36 layers will always be equal to zero, which means x+conv(x) will always be equal to x.
What has that gained us? The key thing is that those 36 extra layers, as they stand, are an identity mapping, but they have parameters, which means they are trainable. So, we can start with our best 20-layer model, add these 36 extra layers which initially do nothing at all, and then fine-tune the whole 56-layer model. Those extra 36 layers can then learn the parameters that make them most useful.
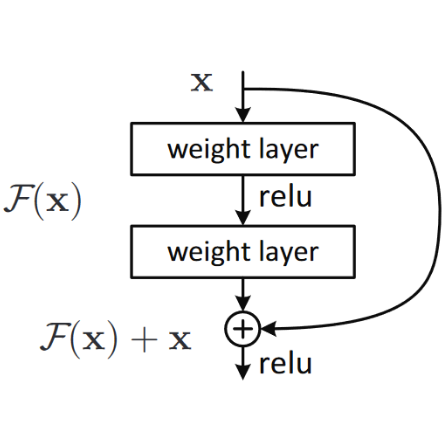
The ResNet paper actually proposed a variant of this, which is to instead "skip over" every second convolution, so effectively we get x+conv2(conv1(x)). This is shown by the diagram in <> (from the paper).</p>
</div>
</div>
</div>
Important: BatchNorm again, i need to learn how gamma and beta works and why.
What is under the hood in a Resnet
:Instead of hoping each few stacked layers directly fit a desired underlying mapping, we explicitly let these layers fit a residual mapping. Formally, denoting the desired underlying mapping as H(x), we let the stacked nonlinear layers fit another mapping of F(x) := H(x)−x. The original mapping is recast into F(x)+x. We hypothesize that it is easier to optimize the residual mapping than to optimize the original, unreferenced mapping. To the extreme, if an identity mapping were optimal, it would be easier to push the residual to zero than to fit an identity mapping by a stack of nonlinear layers.
Note: Again, this is rather inaccessible prose—so let’s try to restate it in plain English! If the outcome of a given layer is x, when using a ResNet block that returns y = x+block(x) we’re not asking the block to predict y, we are asking it to predict the difference between y and x. So the job of those blocks isn’t to predict certain features, but to minimize the error between x and the desired y. A ResNet is, therefore, good at learning about slight differences between doing nothing and passing though a block of two convolutional layers (with trainable weights). This is how these models got their name: they’re predicting residuals (reminder: "residual" is prediction minus target).
One key concept that both of these two ways of thinking about ResNets share is the idea of ease of learning. This is an important theme. Recall the universal approximation theorem, which states that a sufficiently large network can learn anything. This is still true, but there turns out to be a very important difference between what a network can learn in principle, and what it is easy for it to learn with realistic data and training regimes. Many of the advances in neural networks over the last decade have been like the ResNet block: the result of realizing how to make something that was always possible actually feasible.
Note: True Identity Path: The original paper didn’t actually do the trick of using zero for the initial value of gamma in the last batchnorm layer of each block; that came a couple of years later. So, the original version of ResNet didn’t quite begin training with a truly identity path through the ResNet blocks, but nonetheless having the ability to "navigate through" the skip connections did indeed make it train better. Adding the batchnorm gamma init trick made the models train at even higher learning rates.
Here's the definition of a simple ResNet block (where norm_type=NormType.BatchZero causes fastai to init the gamma weights of the last batchnorm layer to zero):
Nice exlanations of F(x)+x is here: roll it back a couple of minutes.
/home/niyazi/anaconda3/envs/fastbook/lib/python3.8/site-packages/torch/nn/functional.py:718: UserWarning: Named tensors and all their associated APIs are an experimental feature and subject to change. Please do not use them for anything important until they are released as stable. (Triggered internally at /opt/conda/conda-bld/pytorch_1623448278899/work/c10/core/TensorImpl.h:1156.)
return torch.max_pool2d(input, kernel_size, stride, padding, dilation, ceil_mode)