Chapter 13 - Convolutional Neural Networks
This is almost same with the original notebook.I took some notes but nothing added. It must be read from start to end.



- Convolutional Neural Networks

#!pip install -Uqq fastbook
import fastbook
fastbook.setup_book()
from fastai.vision.all import *
from fastbook import *
matplotlib.rc('image', cmap='Greys')
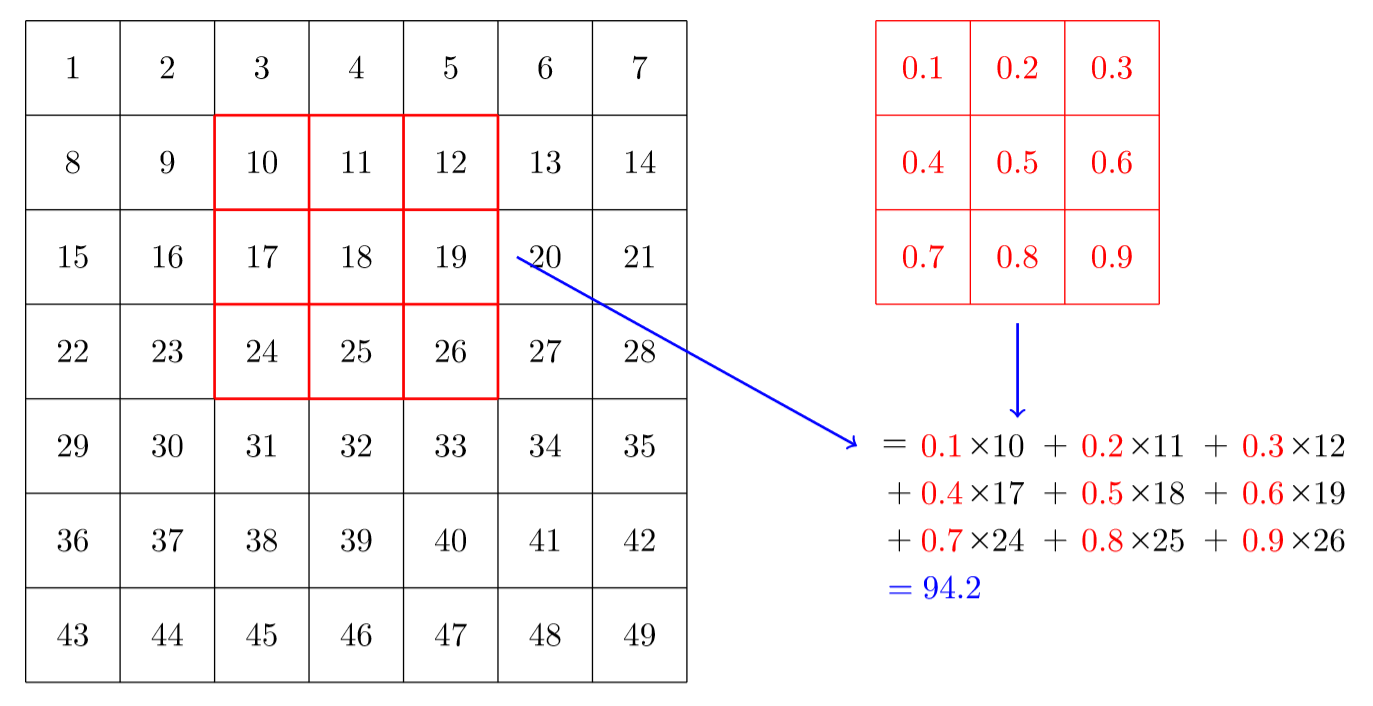
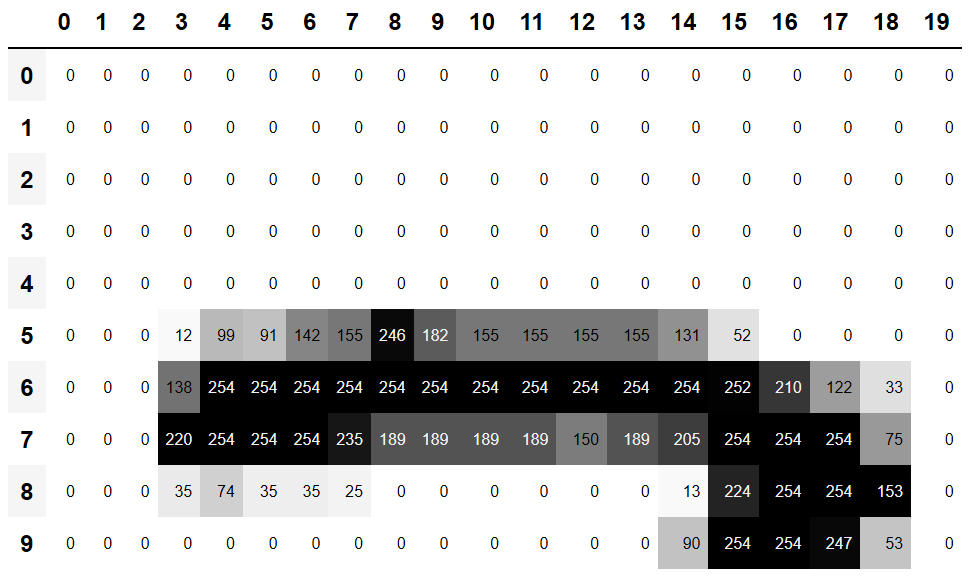
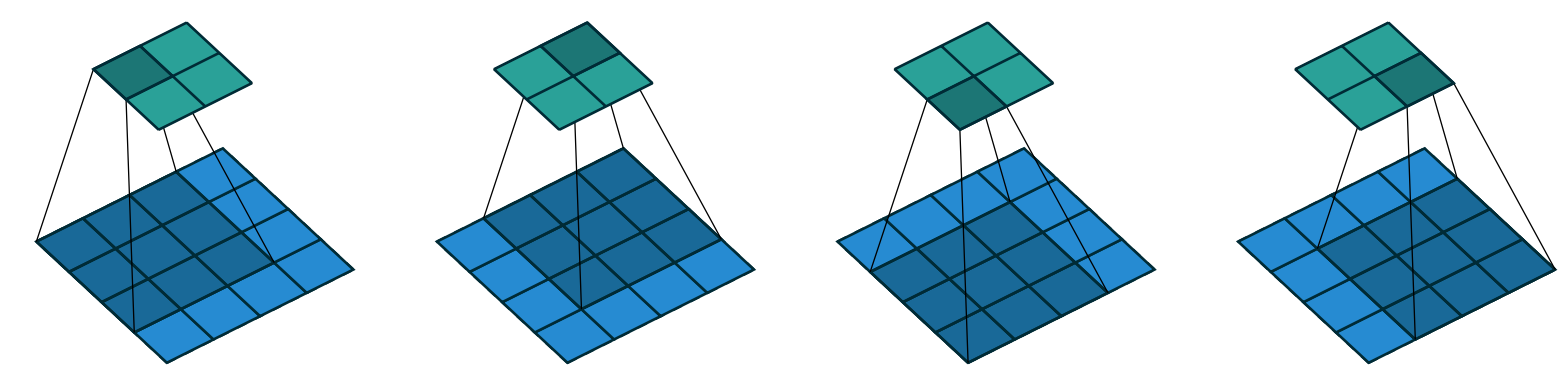
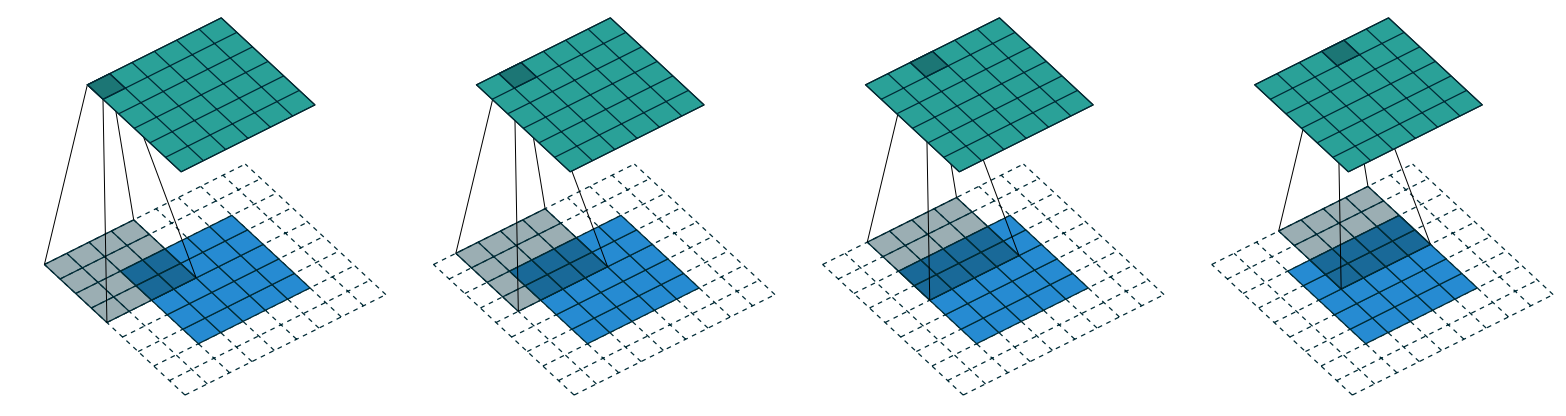
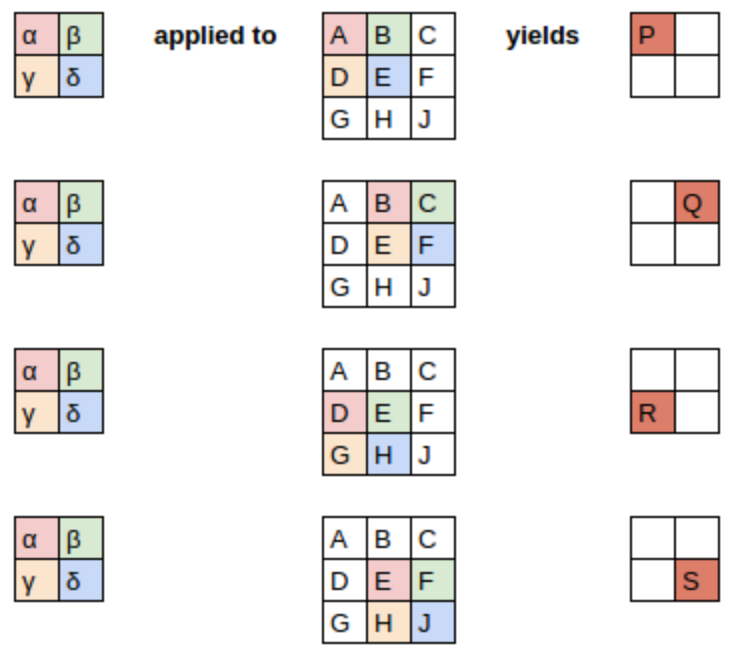
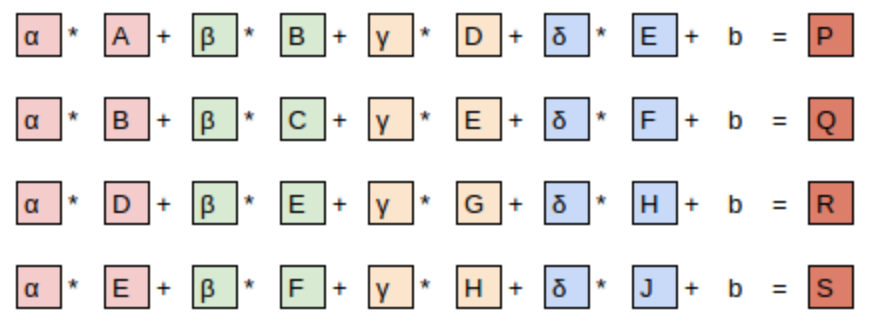
In < In this chapter, we will begin by digging into what convolutions are and building a CNN from scratch. We will then study a range of techniques to improve training stability and learn all the tweaks the library usually applies for us to get great results. One of the most powerful tools that machine learning practitioners have at their disposal is feature engineering. A feature is a transformation of the data which is designed to make it easier to model. For instance, the jargon:Feature engineering: Creating new transformations of the input data in order to make it easier to model. In the context of an image, a feature is a visually distinctive attribute. For example, the number 7 is characterized by a horizontal edge near the top of the digit, and a top-right to bottom-left diagonal edge underneath that. On the other hand, the number 3 is characterized by a diagonal edge in one direction at the top left and bottom right of the digit, the opposite diagonal at the bottom left and top right, horizontal edges at the middle, top, and bottom, and so forth. So what if we could extract information about where the edges occur in each image, and then use that information as our features, instead of raw pixels? It turns out that finding the edges in an image is a very common task in computer vision, and is surprisingly straightforward. To do it, we use something called a convolution. A convolution requires nothing more than multiplication, and addition—two operations that are responsible for the vast majority of work that we will see in every single deep learning model in this book! A convolution applies a kernel across an image. A kernel is a little matrix, such as the 3×3 matrix in the top right of < The 7×7 grid to the left is the image we're going to apply the kernel to. The convolution operation multiplies each element of the kernel by each element of a 3×3 block of the image. The results of these multiplications are then added together. The diagram in < Let's do this with code. First, we create a little 3×3 matrix like so: We're going to call this our kernel (because that's what fancy computer vision researchers call these). And we'll need an image, of course: Now we're going to take the top 3×3-pixel square of our image, and multiply each of those values by each item in our kernel. Then we'll add them up, like so: Not very interesting so far—all the pixels in the top-left corner are white. But let's pick a couple of more interesting spots: There's a top edge at cell 5,8. Let's repeat our calculation there: There's a right edge at cell 8,18. What does that give us?: As you can see, this little calculation is returning a high number where the 3×3-pixel square represents a top edge (i.e., where there are low values at the top of the square, and high values immediately underneath). That's because the Let's look a tiny bit at the math. The filter will take any window of size 3×3 in our images, and if we name the pixel values like this:
$$\begin{matrix} a1 & a2 & a3 \\ a4 & a5 & a6 \\ a7 & a8 & a9 \end{matrix}$$
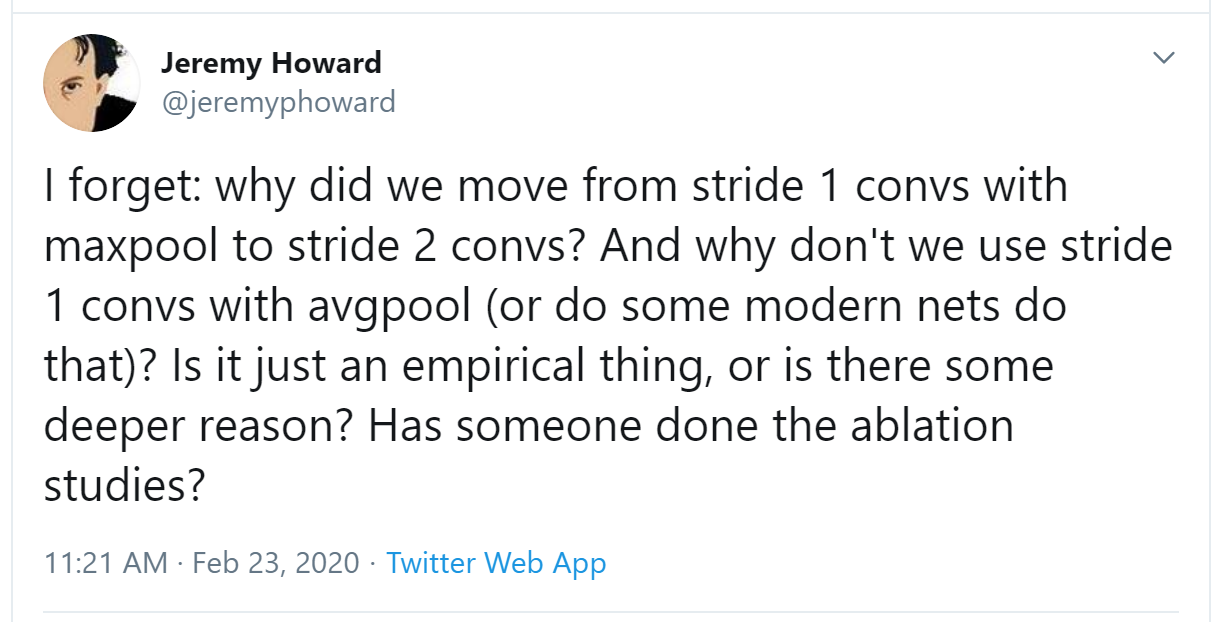
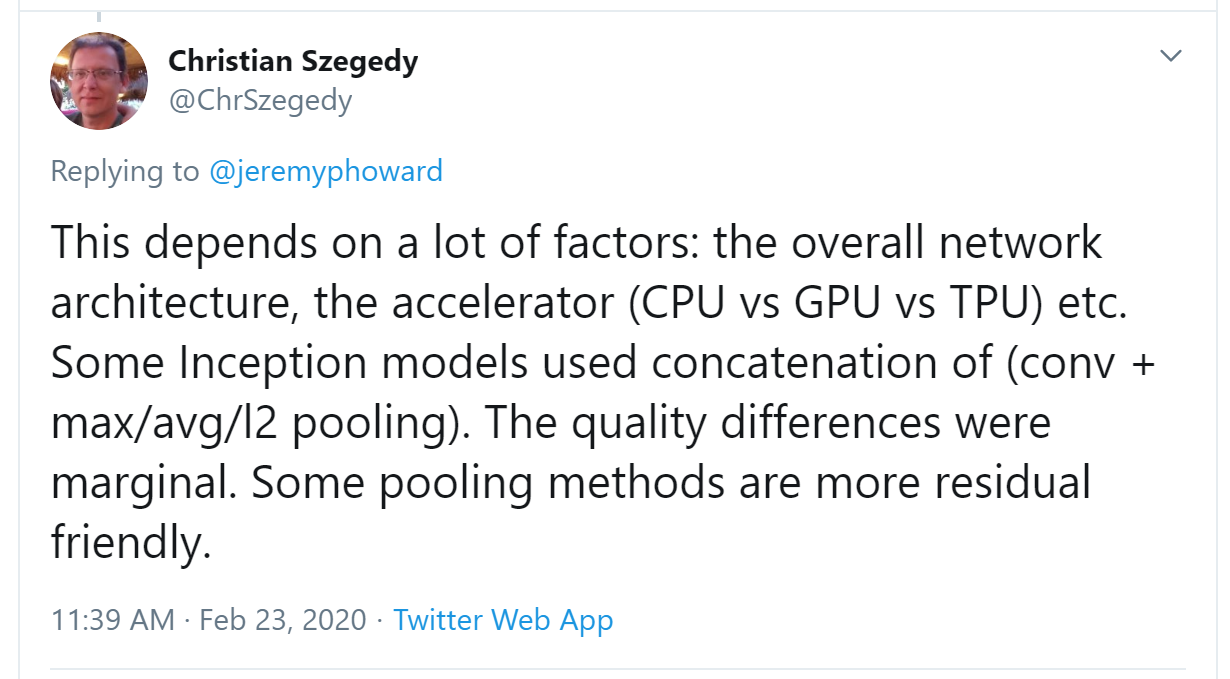
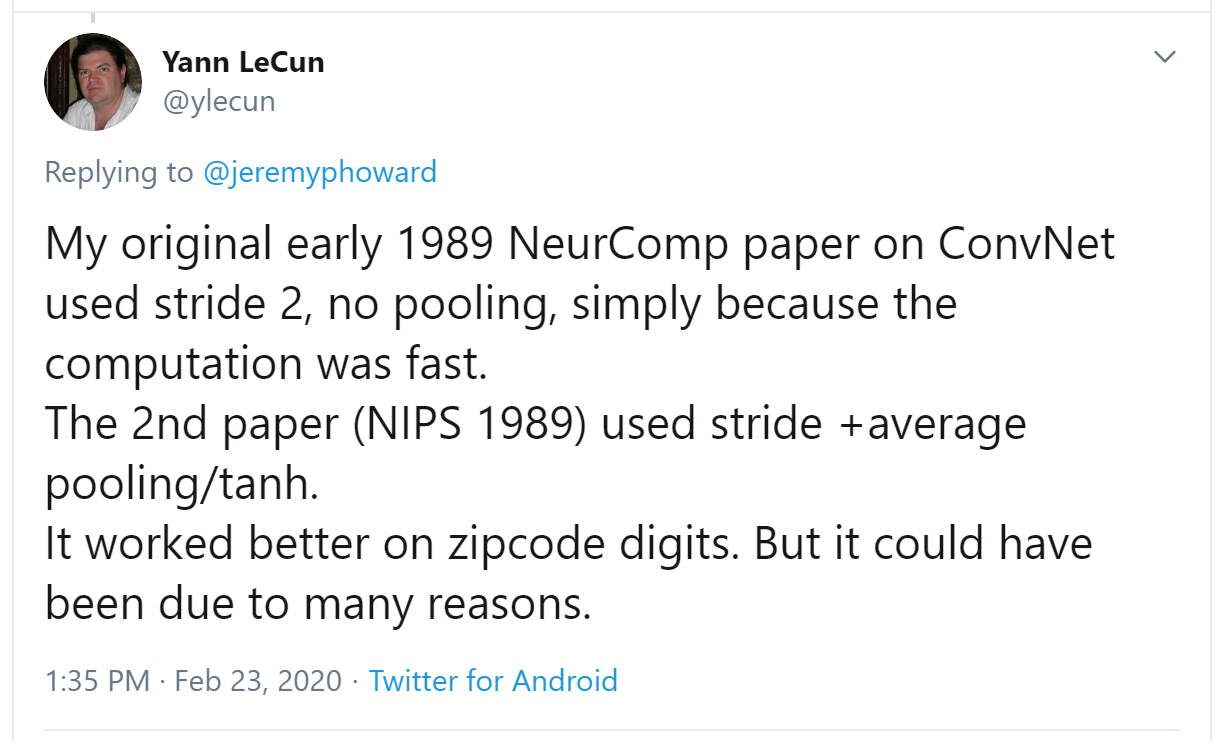
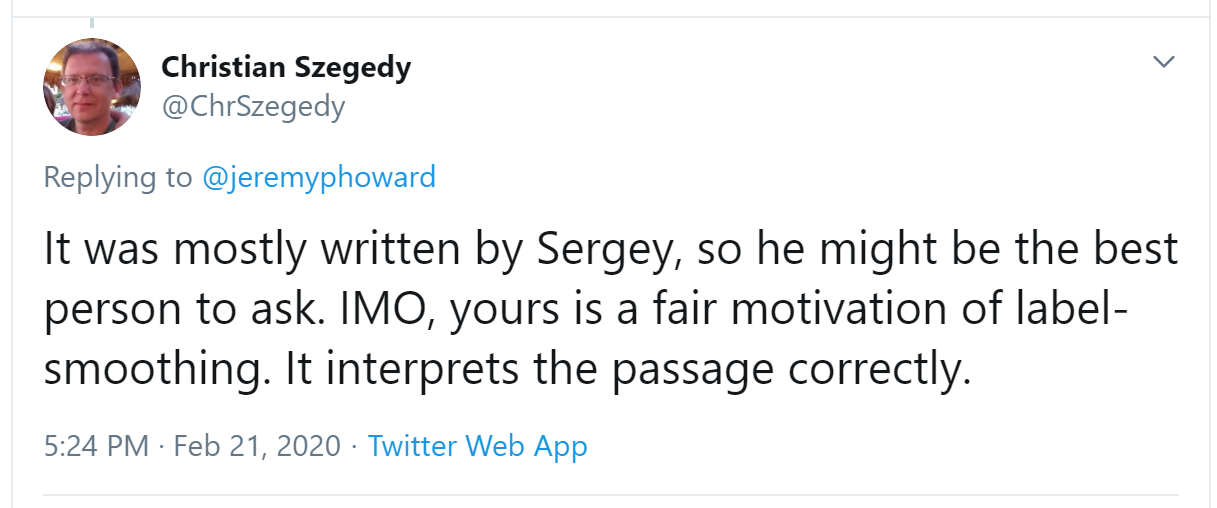
it will return $-a1-a2-a3+a7+a8+a9$. If we are in a part of the image where $a1$, $a2$, and $a3$ add up to the same as $a7$, $a8$, and $a9$, then the terms will cancel each other out and we will get 0. However, if $a7$ is greater than $a1$, $a8$ is greater than $a2$, and $a9$ is greater than $a3$, we will get a bigger number as a result. So this filter detects horizontal edges—more precisely, edges where we go from bright parts of the image at the top to darker parts at the bottom. Changing our filter to have the row of Let's create a function to do this for one location, and check it matches our result from before: But note that we can't apply it to the corner (e.g., location 0,0), since there isn't a complete 3×3 square there. We can map To get a grid of coordinates we can use a nested list comprehension, like so: Here's the result of applying our kernel over a coordinate grid: Looking good! Our top edges are black, and bottom edges are white (since they are the opposite of top edges). Now that our image contains negative numbers too, We can try the same thing for left edges: As we mentioned before, a convolution is the operation of applying such a kernel over a grid in this way. In the paper "A Guide to Convolution Arithmetic for Deep Learning" there are many great diagrams showing how image kernels can be applied. Here's an example from the paper showing (at the bottom) a light blue 4×4 image, with a dark blue 3×3 kernel being applied, creating a 2×2 green output activation map at the top. Look at the shape of the result. If the original image has a height of We won't implement this convolution function from scratch, but use PyTorch's implementation instead (it is way faster than anything we could do in Python). Convolution is such an important and widely used operation that PyTorch has it built in. It's called Here The reason for these extra axes is that PyTorch has a few tricks up its sleeve. The first trick is that PyTorch can apply a convolution to multiple images at the same time. That means we can call it on every item in a batch at once! The second trick is that PyTorch can apply multiple kernels at the same time. So let's create the diagonal-edge kernels too, and then stack all four of our edge kernels into a single tensor: To test this, we'll need a By default, fastai puts data on the GPU when using data blocks. Let's move it to the CPU for our examples: One batch contains 64 images, each of 1 channel, with 28×28 pixels. We'll see how to handle more than one channel later in this chapter. Kernels passed to This is now the correct shape for The output shape shows we gave 64 images in the mini-batch, 4 kernels, and 26×26 edge maps (we started with 28×28 images, but lost one pixel from each side as discussed earlier). We can see we get the same results as when we did this manually: The most important trick that PyTorch has up its sleeve is that it can use the GPU to do all this work in parallel—that is, applying multiple kernels, to multiple images, across multiple channels. Doing lots of work in parallel is critical to getting GPUs to work efficiently; if we did each of these operations one at a time, we'd often run hundreds of times slower (and if we used our manual convolution loop from the previous section, we'd be millions of times slower!). Therefore, to become a strong deep learning practitioner, one skill to practice is giving your GPU plenty of work to do at a time. It would be nice to not lose those two pixels on each axis. The way we do that is to add padding, which is simply additional pixels added around the outside of our image. Most commonly, pixels of zeros are added. With appropriate padding, we can ensure that the output activation map is the same size as the original image, which can make things a lot simpler when we construct our architectures. < With a 5×5 input, 4×4 kernel, and 2 pixels of padding, we end up with a 6×6 activation map, as we can see in < If we add a kernel of size So far, when we have applied the kernel to the grid, we have moved it one pixel over at a time. But we can jump further; for instance, we could move over two pixels after each kernel application, as in < In an image of size Let's now take a look at how the pixel values of the result of our convolutions are computed. To explain the math behind convolutions, fast.ai student Matt Kleinsmith came up with the very clever idea of showing CNNs from different viewpoints. In fact, it's so clever, and so helpful, we're going to show it here too! Here's our 3×3 pixel image, with each pixel labeled with a letter: And here's our kernel, with each weight labeled with a Greek letter: Since the filter fits in the image four times, we have four results: < The equation view is in < Notice that the bias term, b, is the same for each section of the image. You can consider the bias as part of the filter, just like the weights (α, β, γ, δ) are part of the filter. Here's an interesting insight—a convolution can be represented as a special kind of matrix multiplication, as illustrated in < The zeros correspond to the pixels that the filter can't touch. Each row of the weight matrix corresponds to one application of the filter. Now that we understand what a convolution is, let's use them to build a neural net. There is no reason to believe that some particular edge filters are the most useful kernels for image recognition. Furthermore, we've seen that in later layers convolutional kernels become complex transformations of features from lower levels, but we don't have a good idea of how to manually construct these. Instead, it would be best to learn the values of the kernels. We already know how to do this—SGD! In effect, the model will learn the features that are useful for classification. When we use convolutions instead of (or in addition to) regular linear layers we create a convolutional neural network (CNN). Let's go back to the basic neural network we had in < We can view a model's definition: We now want to create a similar architecture to this linear model, but using convolutional layers instead of linear. Here's a possible architecture: One thing to note here is that we didn't need to specify 28×28 as the input size. That's because a linear layer needs a weight in the weight matrix for every pixel, so it needs to know how many pixels there are, but a convolution is applied over each pixel automatically. The weights only depend on the number of input and output channels and the kernel size, as we saw in the previous section. Think about what the output shape is going to be, then let's try it and see: This is not something we can use to do classification, since we need a single output activation per image, not a 28×28 map of activations. One way to deal with this is to use enough stride-2 convolutions such that the final layer is size 1. That is, after one stride-2 convolution the size will be 14×14, after two it will be 7×7, then 4×4, 2×2, and finally size 1. Let's try that now. First, we'll define a function with the basic parameters we'll use in each convolution: When we use a stride-2 convolution, we often increase the number of features at the same time. This is because we're decreasing the number of activations in the activation map by a factor of 4; we don't want to decrease the capacity of a layer by too much at a time. jargon:channels and features: These two terms are largely used interchangeably, and refer to the size of the second axis of a weight matrix, which is, the number of activations per grid cell after a convolution. Features is never used to refer to the input data, but channels can refer to either the input data (generally channels are colors) or activations inside the network. Here is how we can build a simple CNN: j:I like to add comments like the ones here after each convolution to show how large the activation map will be after each layer. These comments assume that the input size is 28*28 Now the network outputs two activations, which map to the two possible levels in our labels: We can now create our To see exactly what's going on in the model, we can use Note that the output of the final Let's see if this trains! Since this is a deeper network than we've built from scratch before, we'll use a lower learning rate and more epochs: Success! It's getting closer to the We can see from the summary that we have an input of size So we have 1 input channel, 4 output channels, and a 3×3 kernel. Let's check the weights of the first convolution: The summary shows we have 40 parameters, and We can now use this information to clarify our statement in the previous section: "When we use a stride-2 convolution, we often increase the number of features because we're decreasing the number of activations in the activation map by a factor of 4; we don't want to decrease the capacity of a layer by too much at a time." There is one bias for each channel. (Sometimes channels are called features or filters when they are not input channels.) The output shape is What happened here is that our stride-2 convolution halved the grid size from Another way to think of this is based on receptive fields. The receptive field is the area of an image that is involved in the calculation of a layer. On the book's website, you'll find an Excel spreadsheet called conv-example.xlsx that shows the calculation of two stride-2 convolutional layers using an MNIST digit. Each layer has a single kernel. < Here, the cell with the green border is the cell we clicked on, and the blue highlighted cells are its precedents—that is, the cells used to calculate its value. These cells are the corresponding 3×3 area of cells from the input layer (on the left), and the cells from the filter (on the right). Let's now click trace precedents again, to see what cells are used to calculate these inputs. < In this example, we have just two convolutional layers, each of stride 2, so this is now tracing right back to the input image. We can see that a 7×7 area of cells in the input layer is used to calculate the single green cell in the Conv2 layer. This 7×7 area is the receptive field in the input of the green activation in Conv2. We can also see that a second filter kernel is needed now, since we have two layers. As you see from this example, the deeper we are in the network (specifically, the more stride-2 convs we have before a layer), the larger the receptive field for an activation in that layer. A large receptive field means that a large amount of the input image is used to calculate each activation in that layer is. We now know that in the deeper layers of the network we have semantically rich features, corresponding to larger receptive fields. Therefore, we'd expect that we'd need more weights for each of our features to handle this increasing complexity. This is another way of saying the same thing we mentioned in the previous section: when we introduce a stride-2 conv in our network, we should also increase the number of channels. When writing this particular chapter, we had a lot of questions we needed answers for, to be able to explain CNNs to you as best we could. Believe it or not, we found most of the answers on Twitter. We're going to take a quick break to talk to you about that now, before we move on to color images. We are not, to say the least, big users of social networks in general. But our goal in writing this book is to help you become the best deep learning practitioner you can, and we would be remiss not to mention how important Twitter has been in our own deep learning journeys. You see, there's another part of Twitter, far away from Donald Trump and the Kardashians, which is the part of Twitter where deep learning researchers and practitioners talk shop every day. As we were writing this section, Jeremy wanted to double-check that what we were saying about stride-2 convolutions was accurate, so he asked on Twitter: A few minutes later, this answer popped up: Christian Szegedy is the first author of Inception, the 2014 ImageNet winner and source of many key insights used in modern neural networks. Two hours later, this appeared: Do you recognize that name? You saw it in < Jeremy also asked on Twitter for help checking our description of label smoothing in < Many of the top people in deep learning today are Twitter regulars, and are very open about interacting with the wider community. One good way to get started is to look at a list of Jeremy's recent Twitter likes, or Sylvain's. That way, you can see a list of Twitter users that we think have interesting and useful things to say. Twitter is the main way we both stay up to date with interesting papers, software releases, and other deep learning news. For making connections with the deep learning community, we recommend getting involved both in the fast.ai forums and on Twitter. That said, let's get back to the meat of this chapter. Up until now, we have only shown you examples of pictures in black and white, with one value per pixel. In practice, most colored images have three values per pixel to define their color. We'll look at working with color images next. A colour picture is a rank-3 tensor: The first axis contains the channels, red, green, and blue: We saw what the convolution operation was for one filter on one channel of the image (our examples were done on a square). A convolutional layer will take an image with a certain number of channels (three for the first layer for regular RGB color images) and output an image with a different number of channels. Like our hidden size that represented the numbers of neurons in a linear layer, we can decide to have as many filters as we want, and each of them will be able to specialize, some to detect horizontal edges, others to detect vertical edges and so forth, to give something like we studied in < In one sliding window, we have a certain number of channels and we need as many filters (we don't use the same kernel for all the channels). So our kernel doesn't have a size of 3 by 3, but So, in order to apply a convolution to a color picture we require a kernel tensor with a size that matches the first axis. At each location, the corresponding parts of the kernel and the image patch are multiplied together. These are then all added together, to produce a single number, for each grid location, for each output feature, as shown in < Then we have Additionally, we may want to have a bias for each filter. In the preceding example, the final result for our convolutional layer would be $y_{R} + y_{G} + y_{B} + b$ in that case. Like in a linear layer, there are as many bias as we have kernels, so the biases is a vector of size There are no special mechanisms required when setting up a CNN for training with color images. Just make sure your first layer has three inputs. There are lots of ways of processing color images. For instance, you can change them to black and white, change from RGB to HSV (hue, saturation, and value) color space, and so forth. In general, it turns out experimentally that changing the encoding of colors won't make any difference to your model results, as long as you don't lose information in the transformation. So, transforming to black and white is a bad idea, since it removes the color information entirely (and this can be critical; for instance, a pet breed may have a distinctive color); but converting to HSV generally won't make any difference. Now you know what those pictures in < This is taking the three slices of the convolutional kernel, for each output feature, and displaying them as images. We can see that even though the creators of the neural net never explicitly created kernels to find edges, for instance, the neural net automatically discovered these features using SGD. Now let's see how we can train these CNNs, and show you all the techniques fastai uses under the hood for efficient training. Since we are so good at recognizing 3s from 7s, let's move on to something harder—recognizing all 10 digits. That means we'll need to use The data is in two folders named training and testing, so we have to tell Remember, it's always a good idea to look at your data before you use it: Now that we have our data ready, we can train a simple model on it. Earlier in this chapter, we built a model based on a Let's start with a basic CNN as a baseline. We'll use the same one as earlier, but with one tweak: we'll use more activations. Since we have more numbers to differentiate, it's likely we will need to learn more filters. As we discussed, we generally want to double the number of filters each time we have a stride-2 layer. One way to increase the number of filters throughout our network is to double the number of activations in the first layer–then every layer after that will end up twice as big as in the previous version as well.
As you'll see in a moment, we can look inside our models while they're training in order to try to find ways to make them train better. To do this we use the We want to train quickly, so that means training at a high learning rate. Let's see how we go at 0.06: This didn't train at all well! Let's find out why. One handy feature of the callbacks passed to As expected, the problems get worse towards the end of the network, as the instability and zero activations compound over layers. Let's look at what we can do to make training more stable. Let's see what the penultimate layer looks like: Again, we've got most of our activations near zero. Let's see what else we can do to improve training stability. Our initial weights are not well suited to the task we're trying to solve. Therefore, it is dangerous to begin training with a high learning rate: we may very well make the training diverge instantly, as we've seen. We probably don't want to end training with a high learning rate either, so that we don't skip over a minimum. But we want to train at a high learning rate for the rest of the training period, because we'll be able to train more quickly that way. Therefore, we should change the learning rate during training, from low, to high, and then back to low again. Leslie Smith (yes, the same guy that invented the learning rate finder!) developed this idea in his article "Super-Convergence: Very Fast Training of Neural Networks Using Large Learning Rates". He designed a schedule for learning rate separated into two phases: one where the learning rate grows from the minimum value to the maximum value (warmup), and one where it decreases back to the minimum value (annealing). Smith called this combination of approaches 1cycle training.
In < We can use 1cycle training in fastai by calling We're finally making some progress! It's giving us a reasonable accuracy now. We can view the learning rate and momentum throughout training by calling Smith's original 1cycle paper used a linear warmup and linear annealing. As you can see, we adapted the approach in fastai by combining it with another popular approach: cosine annealing. Let's take a look at our layer stats again: The percentage of near-zero weights is getting much better, although it's still quite high. We can see even more about what's going on in our training using To create :The final plot for each layer is made by stacking the histogram of the activations from each batch along the horizontal axis. So each vertical slice in the visualisation represents the histogram of activations for a single batch. The color intensity corresponds to the height of the histogram, in other words the number of activations in each histogram bin.
< This illustrates why log(f) is more colorful than f when f follows a normal distribution because taking a log changes the Gaussian in a quadratic, which isn't as narrow. So with that in mind, let's take another look at the result for the penultimate layer: This shows a classic picture of "bad training." We start with nearly all activations at zero—that's what we see at the far left, with all the dark blue. The bright yellow at the bottom represents the near-zero activations. Then, over the first few batches we see the number of nonzero activations exponentially increasing. But it goes too far, and collapses! We see the dark blue return, and the bottom becomes bright yellow again. It almost looks like training restarts from scratch. Then we see the activations increase again, and collapse again. After repeating this a few times, eventually we see a spread of activations throughout the range. It's much better if training can be smooth from the start. The cycles of exponential increase and then collapse tend to result in a lot of near-zero activations, resulting in slow training and poor final results. One way to solve this problem is to use batch normalization. To fix the slow training and poor final results we ended up with in the previous section, we need to fix the initial large percentage of near-zero activations, and then try to maintain a good distribution of activations throughout training. Sergey Ioffe and Christian Szegedy presented a solution to this problem in the 2015 paper "Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift". In the abstract, they describe just the problem that we've seen:
Batch normalization (often just called batchnorm) works by taking an average of the mean and standard deviations of the activations of a layer and using those to normalize the activations. However, this can cause problems because the network might want some activations to be really high in order to make accurate predictions. So they also added two learnable parameters (meaning they will be updated in the SGD step), usually called That's why our activations can have any mean or variance, independent from the mean and standard deviation of the results of the previous layer. Those statistics are learned separately, making training easier on our model. The behavior is different during training and validation: during training, we use the mean and standard deviation of the batch to normalize the data, while during validation we instead use a running mean of the statistics calculated during training. Let's add a batchnorm layer to and fit our model: That's a great result! Let's take a look at This is just what we hope to see: a smooth development of activations, with no "crashes." Batchnorm has really delivered on its promise here! In fact, batchnorm has been so successful that we see it (or something very similar) in nearly all modern neural networks. An interesting observation about models containing batch normalization layers is that they tend to generalize better than models that don't contain them. Although we haven't as yet seen a rigorous analysis of what's going on here, most researchers believe that the reason for this is that batch normalization adds some extra randomness to the training process. Each mini-batch will have a somewhat different mean and standard deviation than other mini-batches. Therefore, the activations will be normalized by different values each time. In order for the model to make accurate predictions, it will have to learn to become robust to these variations. In general, adding additional randomization to the training process often helps. Since things are going so well, let's train for a few more epochs and see how it goes. In fact, let's increase the learning rate, since the abstract of the batchnorm paper claimed we should be able to "train at much higher learning rates": At this point, I think it's fair to say we know how to recognize digits! It's time to move on to something harder... We've seen that convolutions are just a type of matrix multiplication, with two constraints on the weight matrix: some elements are always zero, and some elements are tied (forced to always have the same value). In < These constraints allow us to use far fewer parameters in our model, without sacrificing the ability to represent complex visual features. That means we can train deeper models faster, with less overfitting. Although the universal approximation theorem shows that it should be possible to represent anything in a fully connected network in one hidden layer, we've seen now that in practice we can train much better models by being thoughtful about network architecture. Convolutions are by far the most common pattern of connectivity we see in neural nets (along with regular linear layers, which we refer to as fully connected), but it's likely that many more will be discovered. We've also seen how to interpret the activations of layers in the network to see whether training is going well or not, and how batchnorm helps regularize the training and makes it smoother. In the next chapter, we will use both of those layers to build the most popular architecture in computer vision: a residual network.add_datepart function that we used for our tabular dataset preprocessing in <
top_edge = tensor([[-1,-1,-1],
[ 0, 0, 0],
[ 1, 1, 1]]).float()
path = untar_data(URLs.MNIST_SAMPLE)
Path.BASE_PATH = path
im3 = Image.open(path/'train'/'3'/'12.png')
show_image(im3);

im3_t = tensor(im3)
im3_t[0:3,0:3] * top_edge
(im3_t[0:3,0:3] * top_edge).sum()
df = pd.DataFrame(im3_t[:10,:20])
df.style.set_properties(**{'font-size':'6pt'}).background_gradient('Greys')
(im3_t[4:7,6:9] * top_edge).sum()
(im3_t[7:10,17:20] * top_edge).sum()
-1 values in our kernel have little impact in that case, but the 1 values have a lot.1s at the top and the -1s at the bottom would detect horizontal edges that go from dark to light. Putting the 1s and -1s in columns versus rows would give us filters that detect vertical edges. Each set of weights will produce a different kind of outcome.def apply_kernel(row, col, kernel):
return (im3_t[row-1:row+2,col-1:col+2] * kernel).sum()
apply_kernel(5,7,top_edge)
apply_kernel() across the coordinate grid. That is, we'll be taking our 3×3 kernel, and applying it to each 3×3 section of our image. For instance, <
[[(i,j) for j in range(1,5)] for i in range(1,5)]
rng = range(1,27)
top_edge3 = tensor([[apply_kernel(i,j,top_edge) for j in rng] for i in rng])
show_image(top_edge3);

matplotlib has automatically changed our colors so that white is the smallest number in the image, black the highest, and zeros appear as gray.left_edge = tensor([[-1,1,0],
[-1,1,0],
[-1,1,0]]).float()
left_edge3 = tensor([[apply_kernel(i,j,left_edge) for j in rng] for i in rng])
show_image(left_edge3);

h and a width of w, how many 3×3 windows can we find? As you can see from the example, there are h-2 by w-2 windows, so the image we get has a result as a height of h-2 and a width of w-2.F.conv2d (recall that F is a fastai import from torch.nn.functional, as recommended by PyTorch). The PyTorch docs tell us that it includes these parameters:
(minibatch, in_channels, iH, iW)
(out_channels, in_channels, kH, kW)
iH,iW is the height and width of the image (i.e., 28,28), and kH,kW is the height and width of our kernel (3,3). But apparently PyTorch is expecting rank-4 tensors for both these arguments, whereas currently we only have rank-2 tensors (i.e., matrices, or arrays with two axes).diag1_edge = tensor([[ 0,-1, 1],
[-1, 1, 0],
[ 1, 0, 0]]).float()
diag2_edge = tensor([[ 1,-1, 0],
[ 0, 1,-1],
[ 0, 0, 1]]).float()
edge_kernels = torch.stack([left_edge, top_edge, diag1_edge, diag2_edge])
edge_kernels.shape
DataLoader and a sample mini-batch. Let's use the data block API:mnist = DataBlock((ImageBlock(cls=PILImageBW), CategoryBlock),
get_items=get_image_files,
splitter=GrandparentSplitter(),
get_y=parent_label)
dls = mnist.dataloaders(path)
xb,yb = first(dls.valid)
xb.shape
xb,yb = to_cpu(xb),to_cpu(yb)
F.conv2d can handle multichannel (i.e., color) images too. A channel is a single basic color in an image—for regular full-color images there are three channels, red, green, and blue. PyTorch represents an image as a rank-3 tensor, with dimensions [channels, rows, columns].F.conv2d need to be rank-4 tensors: [channels_in, features_out, rows, columns]. edge_kernels is currently missing one of these. We need to tell PyTorch that the number of input channels in the kernel is one, which we can do by inserting an axis of size one (this is known as a unit axis) in the first location, where the PyTorch docs show in_channels is expected. To insert a unit axis into a tensor, we use the unsqueeze method:edge_kernels.shape,edge_kernels.unsqueeze(1).shape
edge_kernels. Let's pass this all to conv2d:edge_kernels = edge_kernels.unsqueeze(1)
batch_features = F.conv2d(xb, edge_kernels)
batch_features.shape
show_image(batch_features[0,0]);


ks by ks (with ks an odd number), the necessary padding on each side to keep the same shape is ks//2. An even number for ks would require a different amount of padding on the top/bottom and left/right, but in practice we almost never use an even filter size.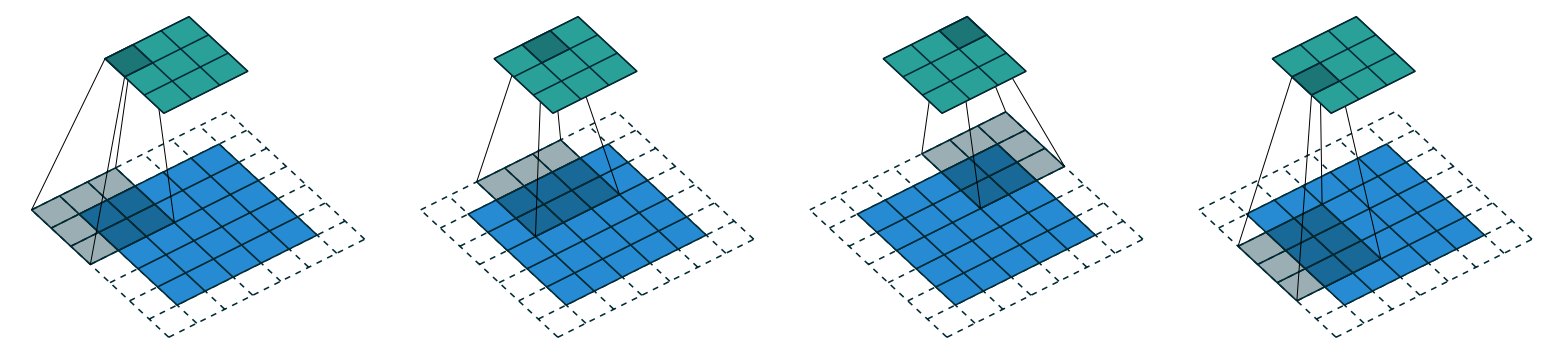
h by w, using a padding of 1 and a stride of 2 will give us a result of size (h+1)//2 by (w+1)//2. The general formula for each dimension is (n + 2*pad - ks)//stride + 1, where pad is the padding, ks, the size of our kernel, and stride is the stride.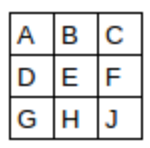
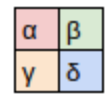
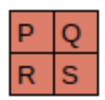

simple_net = nn.Sequential(
nn.Linear(28*28,30),
nn.ReLU(),
nn.Linear(30,1)
)
simple_net
nn.Conv2d is the module equivalent of F.conv2d. It's more convenient than F.conv2d when creating an architecture, because it creates the weight matrix for us automatically when we instantiate it.broken_cnn = sequential(
nn.Conv2d(1,30, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(30,1, kernel_size=3, padding=1)
)
broken_cnn(xb).shape
def conv(ni, nf, ks=3, act=True):
res = nn.Conv2d(ni, nf, stride=2, kernel_size=ks, padding=ks//2)
if act: res = nn.Sequential(res, nn.ReLU())
return res
simple_cnn = sequential(
conv(1 ,4), #14x14
conv(4 ,8), #7x7
conv(8 ,16), #4x4
conv(16,32), #2x2
conv(32,2, act=False), #1x1
Flatten(),
)
simple_cnn(xb).shape
Learner:learn = Learner(dls, simple_cnn, loss_func=F.cross_entropy, metrics=accuracy)
summary:learn.summary()
Conv2d layer is 64x2x1x1. We need to remove those extra 1x1 axes; that's what Flatten does. It's basically the same as PyTorch's squeeze method, but as a module.learn.fit_one_cycle(2, 0.01)
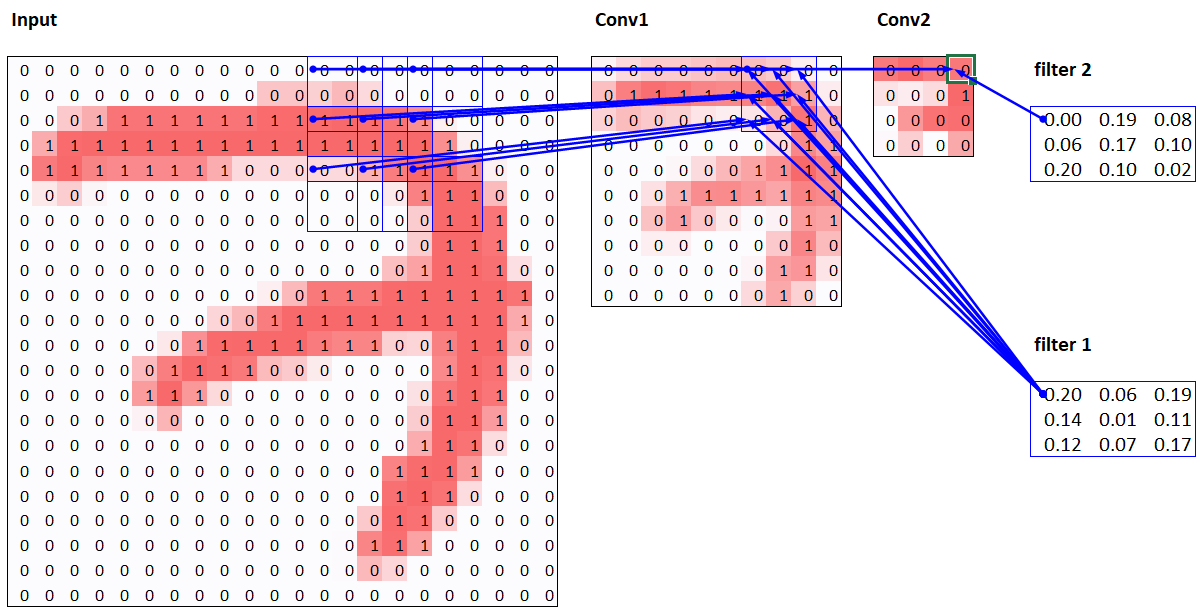
resnet18 result we had, although it's not quite there yet, and it's taking more epochs, and we're needing to use a lower learning rate. We still have a few more tricks to learn, but we're getting closer and closer to being able to create a modern CNN from scratch.64x1x28x28. The axes are batch,channel,height,width. This is often represented as NCHW (where N refers to batch size). Tensorflow, on the other hand, uses NHWC axis order. The first layer is:m = learn.model[0]
m
m[0].weight.shape
4*1*3*3 is 36. What are the other four parameters? Let's see what the bias contains:m[0].bias.shape
64x4x14x14, and this will therefore become the input shape to the next layer. The next layer, according to summary, has 296 parameters. Let's ignore the batch axis to keep things simple. So for each of 14*14=196 locations we are multiplying 296-8=288 weights (ignoring the bias for simplicity), so that's 196*288=56_448 multiplications at this layer. The next layer will have 7*7*(1168-16)=56_448 multiplications.14x14 to 7x7, and we doubled the number of filters from 8 to 16, resulting in no overall change in the amount of computation. If we left the number of channels the same in each stride-2 layer, the amount of computation being done in the net would get less and less as it gets deeper. But we know that the deeper layers have to compute semantically rich features (such as eyes or fur), so we wouldn't expect that doing less computation would make sense.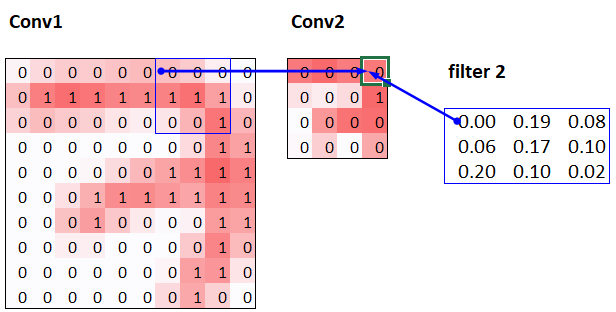
im = image2tensor(Image.open(image_bear()))
im.shape
show_image(im);

_,axs = subplots(1,3)
for bear,ax,color in zip(im,axs,('Reds','Greens','Blues')):
show_image(255-bear, ax=ax, cmap=color)

ch_in (for channels in) is 3 by 3. On each channel, we multiply the elements of our window by the elements of the coresponding filter, then sum the results (as we saw before) and sum over all the filters. In the example given in <

ch_out filters like this, so in the end, the result of our convolutional layer will be a batch of images with ch_out channels and a height and width given by the formula outlined earlier. This give us ch_out tensors of size ch_in x ks x ks that we represent in one big tensor of four dimensions. In PyTorch, the order of the dimensions for those weights is ch_out x ch_in x ks x ks.ch_out.
MNIST instead of MNIST_SAMPLE:path = untar_data(URLs.MNIST)
path.ls()
GrandparentSplitter about that (it defaults to train and valid). We did do that in the get_dls function, which we create to make it easy to change our batch size later:def get_dls(bs=64):
return DataBlock(
blocks=(ImageBlock(cls=PILImageBW), CategoryBlock),
get_items=get_image_files,
splitter=GrandparentSplitter('training','testing'),
get_y=parent_label,
batch_tfms=Normalize()
).dataloaders(path, bs=bs)
dls = get_dls()
dls.show_batch(max_n=9, figsize=(4,4))

conv function like this:def conv(ni, nf, ks=3, act=True):
res = nn.Conv2d(ni, nf, stride=2, kernel_size=ks, padding=ks//2)
if act: res = nn.Sequential(res, nn.ReLU())
return res
def simple_cnn():
return sequential(
conv(1 ,8, ks=5), #14x14
conv(8 ,16), #7x7
conv(16,32), #4x4
conv(32,64), #2x2
conv(64,10, act=False), #1x1
Flatten(),
)
ActivationStats callback, which records the mean, standard deviation, and histogram of activations of every trainable layer (as we've seen, callbacks are used to add behavior to the training loop; we'll explore how they work in <from fastai.callback.hook import *
def fit(epochs=1):
learn = Learner(dls, simple_cnn(), loss_func=F.cross_entropy,
metrics=accuracy, cbs=ActivationStats(with_hist=True))
learn.fit(epochs, 0.06)
return learn
learn = fit()
Learner is that they are made available automatically, with the same name as the callback class, except in snake_case. So, our ActivationStats callback can be accessed through activation_stats. I'm sure you remember learn.recorder... can you guess how that is implemented? That's right, it's a callback called Recorder!ActivationStats includes some handy utilities for plotting the activations during training. plot_layer_stats(idx) plots the mean and standard deviation of the activations of layer number idx, along with the percentage of activations near zero. Here's the first layer's plot:learn.activation_stats.plot_layer_stats(0)

learn.activation_stats.plot_layer_stats(-2)

dls = get_dls(512)
learn = fit()
learn.activation_stats.plot_layer_stats(-2)

fine_tune in fastai.fit_one_cycle:def fit(epochs=1, lr=0.06):
learn = Learner(dls, simple_cnn(), loss_func=F.cross_entropy,
metrics=accuracy, cbs=ActivationStats(with_hist=True))
learn.fit_one_cycle(epochs, lr)
return learn
learn = fit()
plot_sched on learn.recorder. learn.recorder (as the name suggests) records everything that happens during training, including losses, metrics, and hyperparameters such as learning rate and momentum:learn.recorder.plot_sched()

fit_one_cycle provides the following parameters you can adjust:
lr_max:: The highest learning rate that will be used (this can also be a list of learning rates for each layer group, or a Python slice object containing the first and last layer group learning rates)div:: How much to divide lr_max by to get the starting learning ratediv_final:: How much to divide lr_max by to get the ending learning ratepct_start:: What percentage of the batches to use for the warmupmoms:: A tuple (mom1,mom2,mom3) where mom1 is the initial momentum, mom2 is the minimum momentum, and mom3 is the final momentumlearn.activation_stats.plot_layer_stats(-2)

color_dim, passing it a layer index:learn.activation_stats.color_dim(-2)

color_dim was developed by fast.ai in conjunction with a student, Stefano Giomo. Stefano, who refers to the idea as the colorful dimension, provides an in-depth explanation of the history and details behind the method. The basic idea is to create a histogram of the activations of a layer, which we would hope would follow a smooth pattern such as the normal distribution (colorful_dist).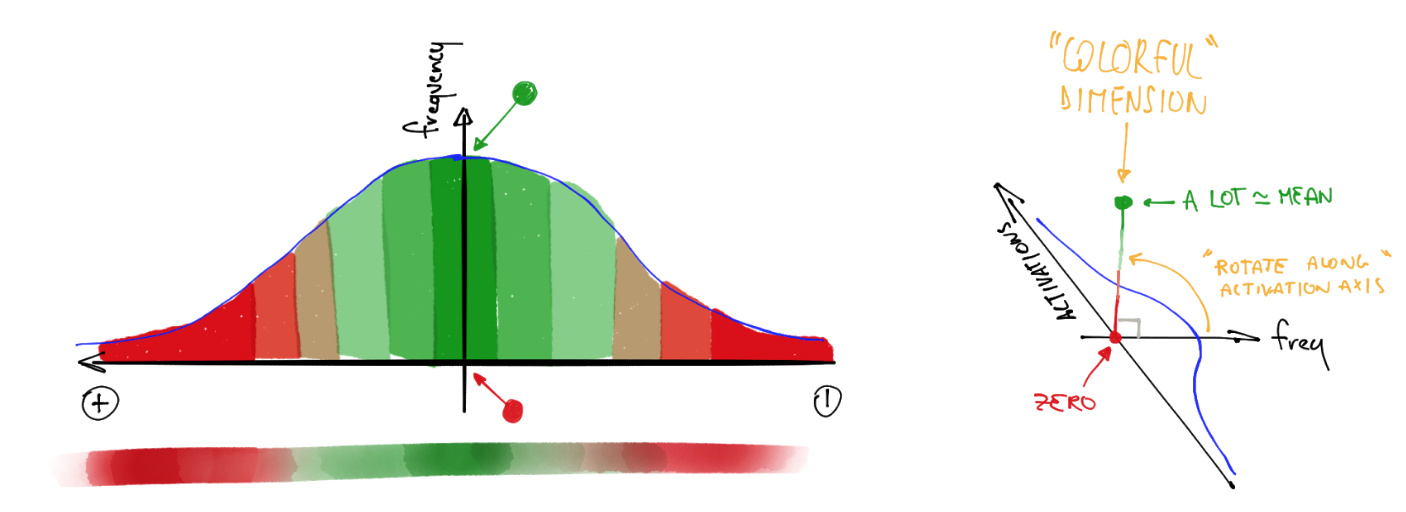
color_dim, we take the histogram shown on the left here, and convert it into just the colored representation shown at the bottom. Then we flip it on its side, as shown on the right. We found that the distribution is clearer if we take the log of the histogram values. Then, Stefano describes: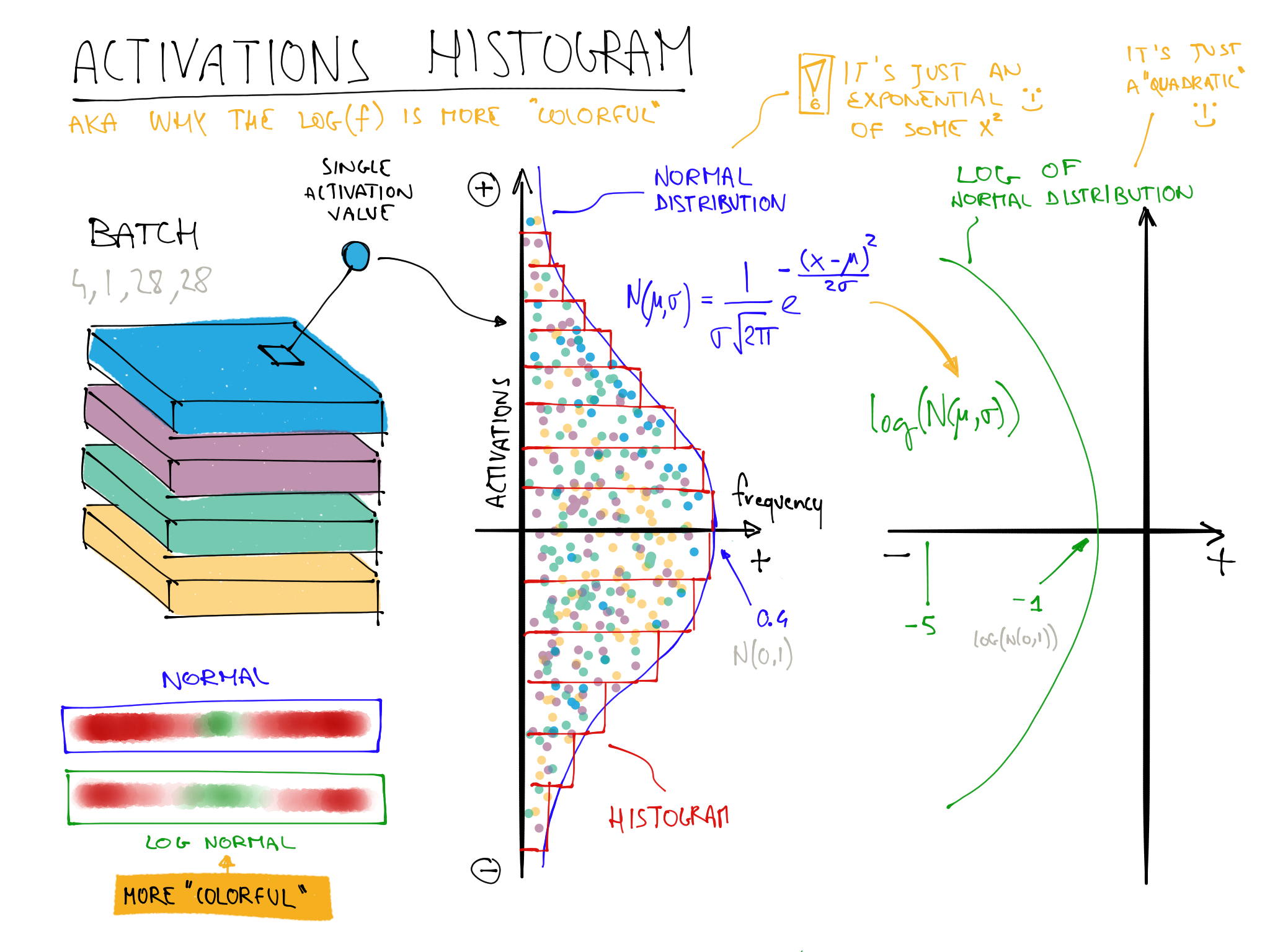
learn.activation_stats.color_dim(-2)
gamma and beta. After normalizing the activations to get some new activation vector y, a batchnorm layer returns gamma*y + beta.conv:def conv(ni, nf, ks=3, act=True):
layers = [nn.Conv2d(ni, nf, stride=2, kernel_size=ks, padding=ks//2)]
if act: layers.append(nn.ReLU())
layers.append(nn.BatchNorm2d(nf))
return nn.Sequential(*layers)
learn = fit()
color_dim:learn.activation_stats.color_dim(-4)

learn = fit(5, lr=0.1)
input and weight parameters to PyTorch's 2D convolution?Flatten? Where does it need to be included in the MNIST CNN? Why?7*7*(1168-16) multiplications?DataLoaders?simple_cnn)?ActivationStats save for each layer?plot_layer_stats? What does the x-axis represent?color_dim plot represent?color_dim? Why?
conv. Does it make a difference? See what you can find out about what order is recommended, and why.