Resnet - Implementation from scratch
This is my first attempt to implement a NN architecture from scratch. It took much more time than I expected, after three videos and this notebook I believe, I'm in a better position to understand the Resnets and CNNs in general. The purpose of this blog post and the companion videos are to document my learning process, get experience in coding and understand published papers. Please check my resources below. I believe it is the most important part of this notebook.



- What is Resnet?
- Resnet From Scratch
- Training with Fast AI
- Video - 2 - Resnet Class Implementation - Resnet From Scratch
- Dataset: IMAGENETTE_160
- New Resnet instance:
- Create a learner.
- Training:
- Video - 3 - Training 'My Resnet' - Resnet From Scratch
- Pytorch's Resnet34 implementation for Benchmark
- A test for 50 epochs. (%5 better)
- Another test with bigger images. (IMAGENETTE_320)
- Resources:
 Unrelated!
Unrelated!
from fastbook: Resnet: chapter-14
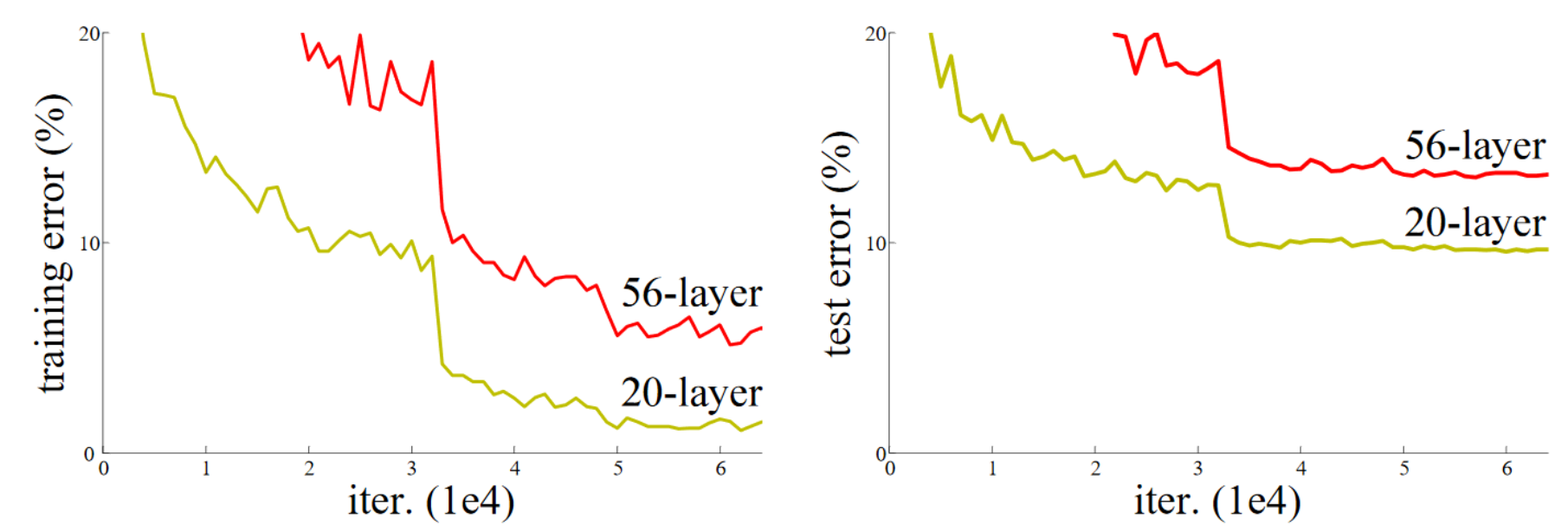
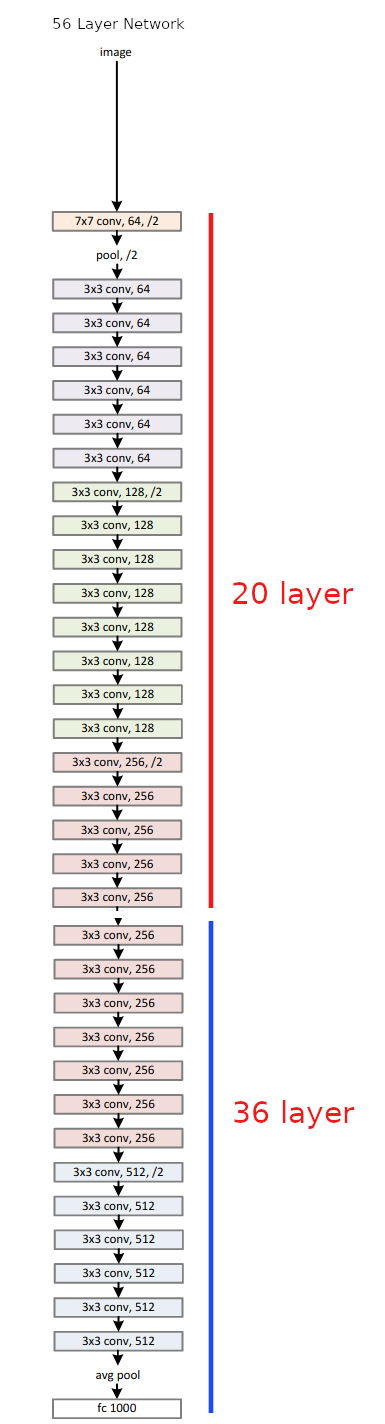
from fastbook: Resnet: chapter-14
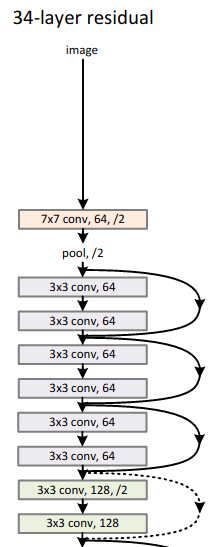
What does that mean?
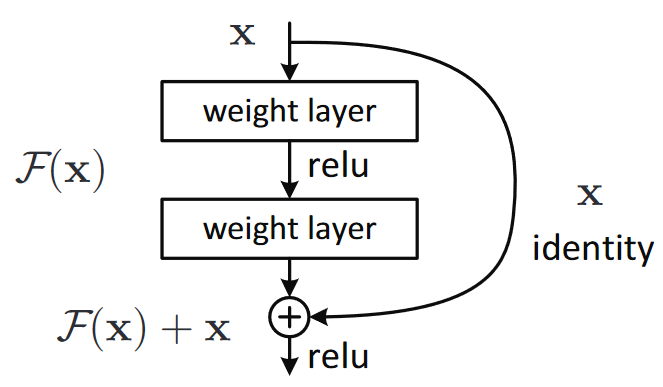
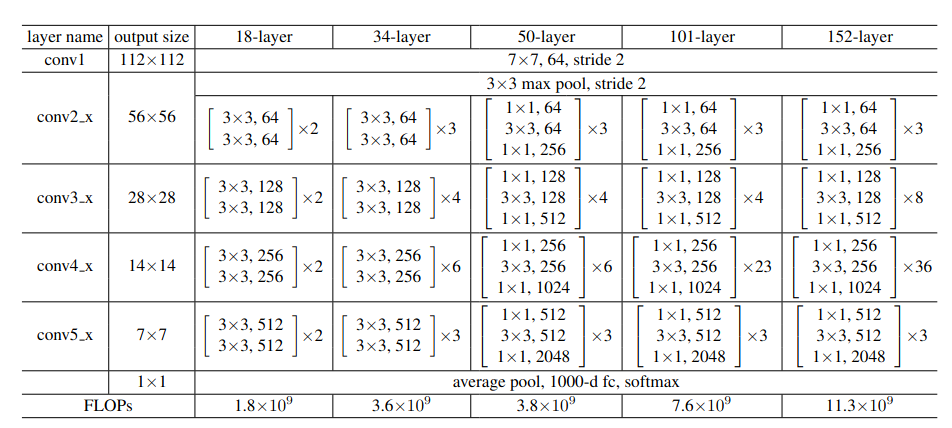
create a basic block/test the block with random tensor with random channel numbers/check downsample
import torch
import torch.nn as nn
import torchvision.models as models
models.resnet34()
class BasicBlock(nn.Module):
def __init__(self,in_chs, out_chs):
super().__init__()
if in_chs==out_chs:
self.stride=1
else:
self.stride=2
self.conv1 = nn.Conv2d(in_chs,out_chs,kernel_size=3, padding=1,stride=self.stride,bias=False)
self.bn1 = nn.BatchNorm2d(out_chs)
self.relu = nn.ReLU()
self.conv2 = nn.Conv2d(out_chs,out_chs,kernel_size=3, padding=1,stride=1,bias=False)
self.bn2 = nn.BatchNorm2d(out_chs)
if in_chs==out_chs:
self.downsample=None
else:
self.downsample= nn.Sequential(#nn.AvgPool2d(2,2),
nn.Conv2d(in_chs,out_chs, kernel_size=1,stride=2,bias=False),
nn.BatchNorm2d(out_chs))
def forward(self,x):
skip_conn=x
x=self.conv1(x)
x=self.bn1(x)
x=self.relu(x)
x=self.conv2(x)
x=self.bn2(x)
if self.downsample:
skip_conn=self.downsample(skip_conn)
x+=skip_conn
x=self.relu(x)
return x
x=torch.randn(1,64,112,112)
basic_block=BasicBlock(64,128)
basic_block(x).shape
#input = torch.randn(1, 64, 128, 128)
#output = m(input)
#output.shape
repeat=[3,4,6,3]
channels=[64,128,256,512]
in_chans=64
for sta,(rep,out_chans) in enumerate(zip(repeat,channels)):
for n in range(rep):
print(sta,in_chans,out_chans)
in_chans=out_chans
def make_block(basic_b=BasicBlock,repeat=[3,4,6,3],channels=[64,128,256,512]):
in_chans=channels[0]
stages=[]
for sta,(rep,out_chans) in enumerate(zip(repeat,channels)):
blocks=[]
for n in range(rep):
blocks.append(basic_b(in_chans,out_chans))
#print(sta,in_chans,out_chans)
in_chans=out_chans
stages.append((f'conv{sta+2}_x',nn.Sequential(*blocks)))
#print(stages)
return stages
class ResneTTe34(nn.Module):
def __init__(self,num_classes):
super().__init__()
#stem
self.conv1=nn.Conv2d(3,64, kernel_size=7, stride=2,padding=3,bias=False)
self.bn1=nn.BatchNorm2d(64)
self.relu=nn.ReLU()
self.max_pool=nn.MaxPool2d(kernel_size=3,stride=2,padding=1)
# res-stages
self.stage_modules= make_block()
for stage in self.stage_modules:
self.add_module(*stage)
self.avg_pool=nn.AdaptiveAvgPool2d(output_size=(1,1))
self.fc=nn.Linear(512,num_classes,bias=True)
#self.softmax=nn.Softmax(dim=1)
def forward(self,x):
x=self.conv1(x)
x=self.bn1(x)
x=self.relu(x)
x=self.max_pool(x)
x=self.conv2_x(x)
x=self.conv3_x(x)
x=self.conv4_x(x)
x=self.conv5_x(x)
x=self.avg_pool(x)
x=torch.flatten(x,1)
x=self.fc(x)
#x=self.softmax(x)
return x
x=torch.randn(1,3,224,224)
my_resnette=ResneTTe34(10)
my_resnette(x).shape
- after conv layers:
torch.Size([1, 512, 7, 7]) - after avg_pool:
torch.Size([1, 512, 1, 1]) - after flatten:
torch.Size([1, 512]) - after fc:
torch.Size([1, 10])
import fastbook
fastbook.setup_book()
from fastai.vision.all import *
A subset of 10 easily classified classes from Imagenet: tench, English springer, cassette player, chain saw, church, French horn, garbage truck, gas pump, golf ball, parachute.
path = untar_data(URLs.IMAGENETTE_160)
data_block=DataBlock(
blocks=(ImageBlock, CategoryBlock), get_items=get_image_files,
splitter=GrandparentSplitter(valid_name='val'),
get_y=parent_label, item_tfms=Resize(160),
batch_tfms=[*aug_transforms(min_scale=0.5, size=160),
Normalize.from_stats(*imagenet_stats)],
)
dls = data_block.dataloaders(path, bs=512)
dls.c
dls.c Number of classes in the dataloaders.
dls.show_batch(max_n=12)

rn=ResneTTe34(10)
rn
learn = Learner(dls, rn, loss_func=nn.CrossEntropyLoss(), metrics=accuracy
).to_fp16()
learn.lr_find()

learn.fit_one_cycle(20, 0.000109)
-
Original Resnet34
lrfindgraph was smoother and I am investigating now -
My Implementation baseline accuracy: %62, PyTorch resnet implementation:74
-
after setting linear chanel
bias=True: %64 -
after setting conv layers
bias=False: %65 -
after
softmaxremoved: %72 -
training 50 epochs
IMAGENETTE_160:%78 -
training 20 epochs with bigger images
IMAGENETTE_320:%82
resnet=models.resnet34()
learn_resnet = Learner(dls, resnet, loss_func=nn.CrossEntropyLoss(), metrics=accuracy
).to_fp16()
learn_resnet.lr_find()

Looks smoother.
learn_resnet.fit_one_cycle(20, 0.000478)
A little better result.
rn_higher_epoch=ResneTTe34(10)
learn_higher_epoch = Learner(dls, rn_higher_epoch, loss_func=nn.CrossEntropyLoss(), metrics=accuracy
).to_fp16()
learn_higher_epoch.lr_find()

learn_higher_epoch.fit_one_cycle(50, 0.000131)
path_320 = untar_data(URLs.IMAGENETTE_320)
data_block_320=DataBlock(
blocks=(ImageBlock, CategoryBlock), get_items=get_image_files,
splitter=GrandparentSplitter(valid_name='val'),
get_y=parent_label, item_tfms=Resize(320),
batch_tfms=[*aug_transforms(min_scale=0.5, size=224),
Normalize.from_stats(*imagenet_stats)],
)
dls_320 = data_block_320.dataloaders(path_320, bs=256)
rn_IM_320=ResneTTe34(10)
learn__IM_320 = Learner(dls_320, rn_IM_320, loss_func=nn.CrossEntropyLoss(), metrics=accuracy
).to_fp16()
learn__IM_320.lr_find()

learn__IM_320.fit_one_cycle(20, 0.0001096)
Resnet paper by Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun https://arxiv.org/abs/1512.03385 , https://arxiv.org/pdf/1512.03385.pdf
W&B Paper Reading Group: ResNets by Aman Arora
W&B Fastbook Reading Group — 14. ResNet
Practical Deep Learning for Coders Book (fastbook)
https://colab.research.google.com/github/fastai/fastbook/blob/master/14_resnet.ipynb
Live Coding Session on ResNet by Aman Arora
[Classic] Deep Residual Learning for Image Recognition (Paper Explained) by Yannic Kilcher
Andrew Ng Resnet videos.